5 Jun 2018
Started the project by contacting Cameron Browne. Got permission from Néstor to use his games. Next day, I got permission from Matt Green to use Sploof. Got permission from Cameron to use his games and use his graphics for making a display.
The games are all described in a BGG list and on nestorgames in the PDF rule book.
Found a Python implementation of Alpha Zero, along with a tutorial. Set up this project to start work. Installed PyTorch and TensorFlow to follow the tutorial.
11 Jun 2018
Discussed board notation with Cameron, comparing the Akron notation and Margo notation. Margo marks all the positions on the board explicitly, and Akron marks the first layer positions with second layer positions marked as prime. I didn’t like the clutter of doubling the markings, but I did prefer the explicit positions over keeping the meaning of prime in your head.
My compromise was to only mark the first layer positions, but use the odd numbers. Then refer to the second layer positions with the even numbers. It’s still explicit, but not cluttered.
+-------------------------------+
| \ A C E G / |
| +--------------___---___--+ |
| | / \_/ \ | |
|7 | . . ( / \ )| 7|
| | \_( B )_/ | |
| | / \___/ \ | |
|5 | . . ( B | B )| 5|
| | ___ ___ \___/ \___/ | |
| | / \ / \ / \ / \ | |
|3 |( | | B | B )| 3|
| | \___/ \___/ \___/ \___/ | |
| | / \ / \ / \ / \ | |
|1 |( B | | | )| 1|
| | \___/ \___/ \___/ \___/ | |
| +-------------------------+ |
| / A C E G \ |
+-------------------------------+
In this example, the stacked black ball is at position 6F.
I successfully played against the 6x6 Othello opponent that comes with the Alpha Zero General project. By “successfully”, I mean that I got it to run, not that I beat it.
I tried training the model for Connect 4 (7x6), and it finished 11 iterations
in about 20 hours. However, I haven’t installed the GPU version of Tensorflow.
When I monitored the GPU with nvidia-smi -l 1, I saw the volatile GPU-util
bounce between 5% and 15% during self play. I didn’t see any change in that
when I stopped the learning, so it was probably my video driver.
As for the result of the training: I beat it in my first two games.
16 Jun 2018
After several hours of futzing, I got the GPU version of Tensorflow installed. Now it finishes 11 iterations in about 3 hours: much faster!. The GPU bounces around 50-60% while playing, and 90-100% while training.
After running 37 iterations overnight, I played against the best model, and it was still pretty dumb. However, when I increased the MCTS iterations from 25 to 500 or 1000, it got much better! At 500, we each won when we were first player. At 1000, it beat me when it was first player, and then beat me again in a long game when I was first player.
Now I think I understand enough to try adding a new set of game rules.
21 Jun 2018
Spent a few nights fighting with the setup tools, and now the Shibumi Games project can use Alpha Zero General as a dependency. I can run Othello from the Shibumi Games project.
Next step: implement Spline!
25 Jun 2018
Implemented the rules of Spline, and tried playing human vs. human.
Next step: write the neural network wrapper.
2 Jul 2018
Tried using the Connect 4 neural network wrapper without changes. I had to hack
the Shibumi Board to hold the pieces in an 8x8 array instead of 4x4x4.
The training session saved eight checkpoints and then quit. Only checkpoint 2 was accepted. I tried playing against the saved model, and beat it two out of two games. It wasn’t completely stupid, but it made some moves I didn’t understand.
Maybe I’ve messed up the symmetry or something. I have to try to understand what the neural network code is really doing. So far, I just copied the existing code.
It would also be nice to let the human player give board coordinates instead of a move index.
I tried just running the training again without change, and it ran for 14 iterations with 7 accepted before I stopped it. Was I just unlucky the first time?
I tried playing against the new network, and we each won one game. My win was strange, because the opponent didn’t play to block it. Maybe there was an unavoidable win somewhere in the next few turns that I didn’t see?
11 Aug 2018
Coming back to this after a couple of months. The last thing I did was to plot the change in strength as I changed the number of iterations. I never got the expected result, so either my player is random, or there’s something wrong with my test.
30 Aug 2018
I decided to get a better understanding of the machine learning tools by taking the Coursera course by Andrew Ng.
21 Oct 2018
Finished the Coursera course, and got a TensorFlow book from the library.
27 Oct 2018
Now that I have a better understanding of the machine learning tools, I want to try and dig into the source code for the alpha-zero-general project. Some ideas:
- Play two different branches against each other. That way you can test whether a change actually improves play.
- Try to measure the benefits of different features: deep learning to score position values, number of iterations of MCTS, architecture of deep learning model. Use existing games in the alpha-zero-general project like Connect Four and Go Bang.
- Try a simpler 3D game, like 3D Tic Tac Toe or Score Four, before going back
to Shibumi games. The
conv3dclass is probably useful.
16 Nov 2018
The upgrade from Ubuntu 16.04 to 18.04 broke my GPU support for Tensorflow.
After breaking my video drivers and reinstalling, I found an article that
describes how to install multiple CUDA libraries. It seems like installing
version 9.0 with the --toolkit option and then pointing to it with
$LD_LIBRARY_PATH was what I needed. I also pointed the /usr/local/cuda
symbolic link back at the 9.1 version, but I’m not sure if that’s necessary.
18 Nov 2018
Now that I’ve got Tensorflow running again, I tried to validate its behaviour. The first thing I tried was to look at how the number of MCTS iterations affects the win rate. I tried pitting players against each other with different numbers of iterations, but the patterns didn’t make any sense. I thought there might be bugs in Spline, so I also tried it with Connect 4. That didn’t make sense either. Most of the win rates were around 50%:
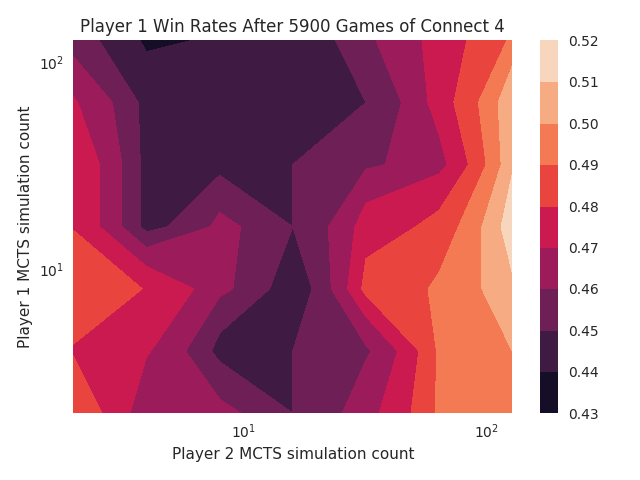
Just to test my expectations, I simulated a simple game where two players flip coins, and the most heads wins. Then I plotted the win rates as each player flips a different number of coins. This was meant to show how I expected the MCTS players’ strengths to vary with the number of iterations.
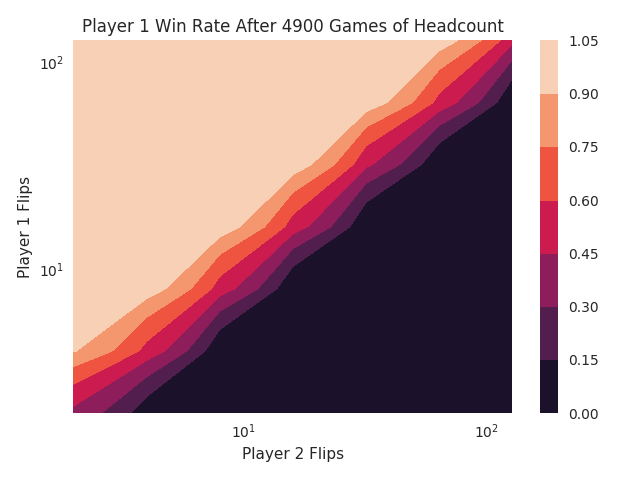
My guess is that the neural network is actually doing a good enough job on these simple games that the MCTS part is irrelevant. I could try a deeper game like Othello, or I could try making a dummy neural network so the MCTS part is more important.
21 Nov 2018
I made a dummy neural network that rated all boards the same, and now the MCTS strength varies with the number of iterations:
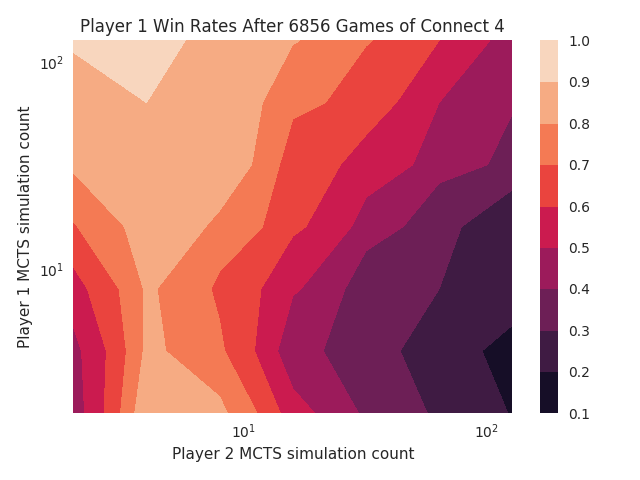
There’s something weird happening between 2 and 4 iterations, so 4 iterations actually looks weaker than 2. Above that, however, the strength changes exactly as I would expect. When both players use 128 iterations, player 1 wins 44% of the games. Is there an advantage for the second player?
The next task is to confirm that the neural network is much stronger than plain MCTS. I’ll plot MCTS with a dummy network against MCTS with a real network, and increase the MCTS iterations with the dummy network.
23 Nov 2018
The results looked promising at first. In this plot, player 1 uses a neural network with 4 MCTS iterations, and player 2 varies between 2 and 128 MCTS iterations without a neural network.
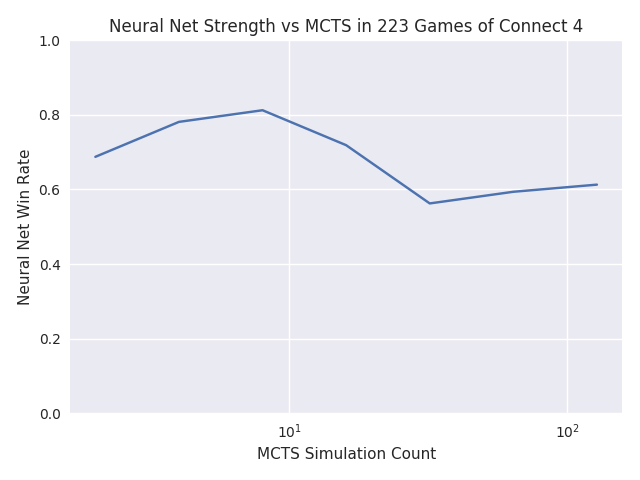
As expected, the MCTS gets stronger with more iterations, and the neural network win rate drops toward 50%. I still don’t understand why the neural network doesn’t do better against 2 and 4 MCTS iterations, but the rest looks good.
However, something went horribly wrong when I left it to run overnight.
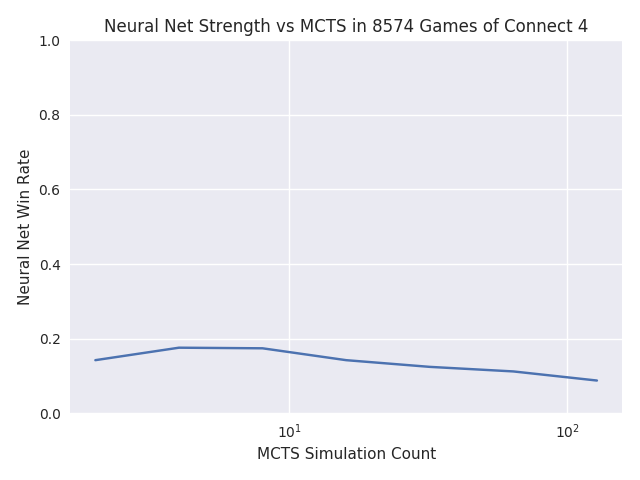
The neural network started losing most games, and the memory usage went way up. There’s probably a memory leak, and maybe it’s holding a whole bunch of data that messes up the statistics.
24 Nov 2018
I think the players are holding all their board positions and statistics from one game to the next, so the MCTS player steadily gets stronger, and memory usage steadily goes up.
25 Nov 2018
You can see in this plot that the memory is climbing steadily, probably because the board positions and statistics aren’t being released.
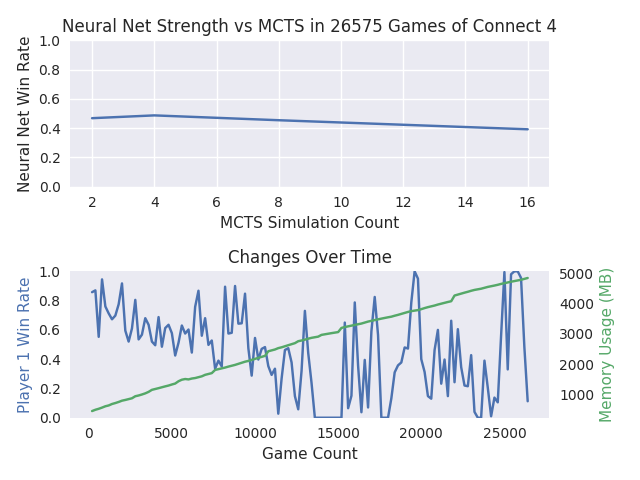
A couple of things I don’t understand, though:
- The memory climbs pretty steadily. I would have expected it to slow down as the most common board positions got recorded. It should only add memory when it finds new positions it hasn’t analysed yet.
- Why does the average strength of the neural network drop? I guess that’s because all those MCTS iterations slowly build up its game knowledge for player 2.
26 Nov 2018
I tried clearing the data structures in the MCTS class, but that introduced
a bug that made it lose all games. I can’t find the bug, so I’m going to take
a break. I think I understand the Alpha Zero technique well enough that I can
rewrite the alpha_zero_general project to make it easier to use as a library.