2 Jan 2019
I added an entry point in setup.py for other projects to define game rules.
Using that entry point within the Zero Play library, I plotted the win rates of
two MCTS players playing Tic Tac Toe:
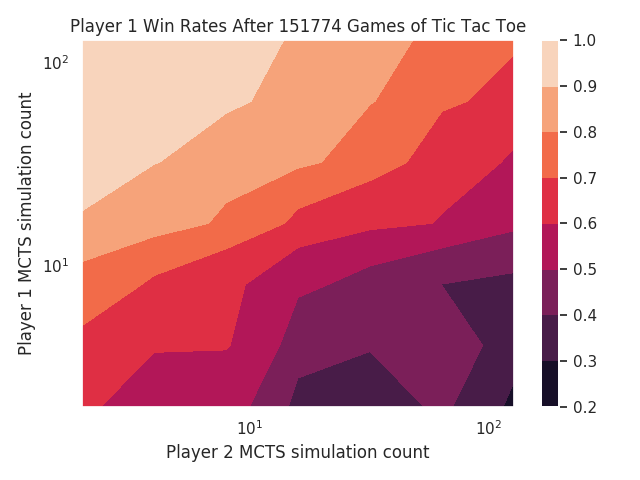
You can see the same general trends as in Connect 4. I’m not sure what’s happening in the bottom right.
Using the same entry point in my Shibumi project, I converted the Spline game to use the new Zero Play library, and plotted the win rates:
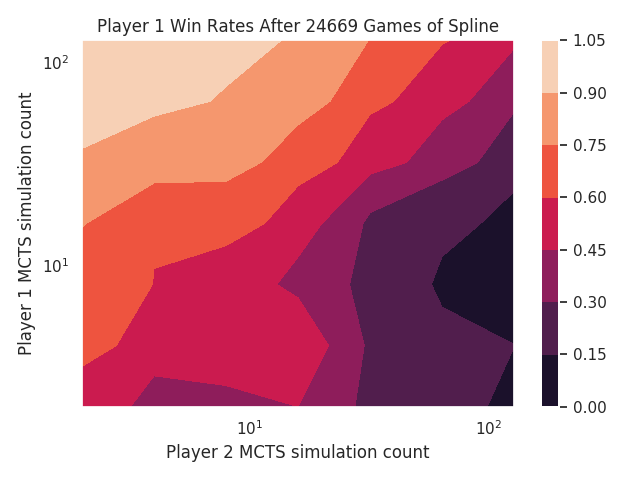
4 Jan 2019
I found a bug in the MCTS code that selects which nodes to expand. It wasn’t taking advantage of the win rates to explore the more successful positions.
With that fixed, the problems at low iterations have gone away:
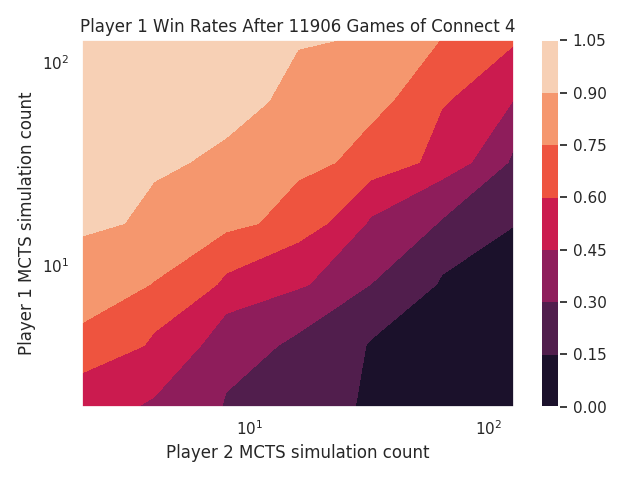
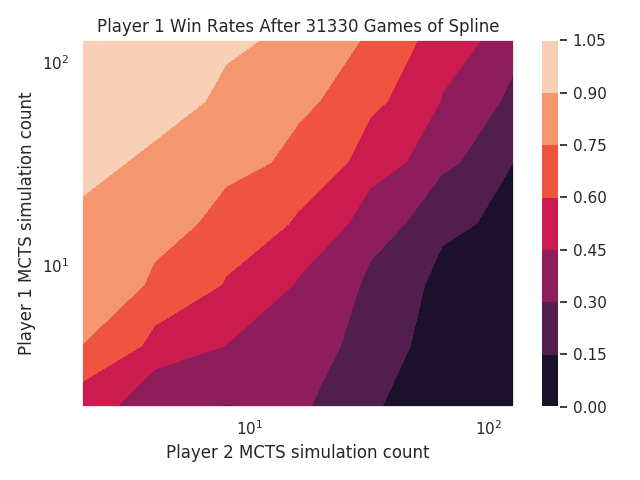
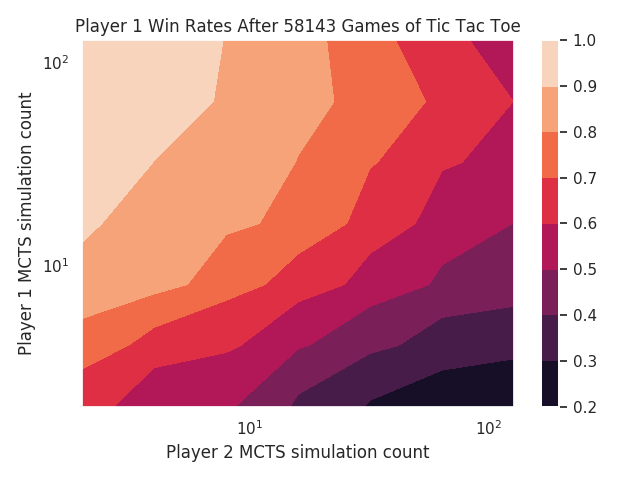
I’m not sure what’s happening with high simulation count for Tic Tac Toe’s first player, but everything else looks beautiful now.
12 Jan 2019
Added the first version of code to train a neural network, and I added a system
so that game and player classes from other projects can add arguments to the
command line. See the CommandParser class in zero_play.py.
16 Feb 2019
Two main tasks in the last month: the neural network sort of works, and I configured Tensorflow to use the GPU. The GPU configuration was a giant pain, again! I had it working a few months ago, but it stopped working for some reason. I did the original setup based on a GPU tutorial that shows how to install multiple driver versions: one that’s compatible with my display and the operating system, and another that’s compatible with Tensorflow. After a bunch of investigation I described in this GPU question on Stack Overflow, I figured out that I had two driver versions squished together in one location. With a bunch of clean up, I got it working again. The GPU version is about 12 times faster than the CPU version.
As for actually using the neural network, it’s not very impressive yet. I found a new way to display the skill of a player, by comparing it to several strengths of a basic MCTS player using simple playouts to value board positions.
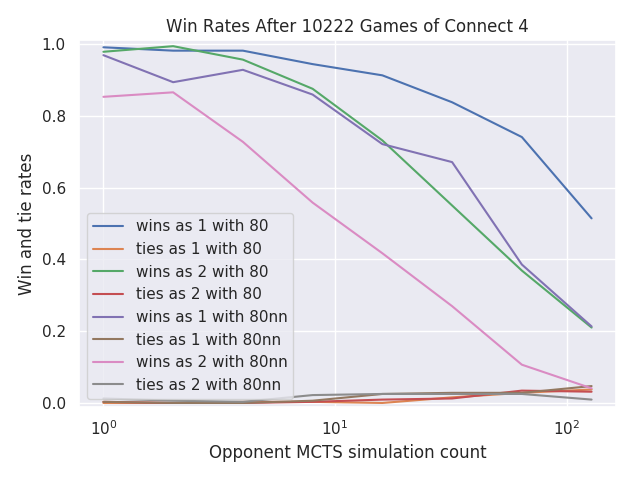
Here, the blue and green lines show a basic MCTS player using simple playouts and 80 search iterations for each move. The blue line is the win rate as player 1 against the same player with increasing numbers of search iterations. The green line is the win rate as player 2. Unsurprisingly, both win rates drop as the opponent strength increases.
The sad part is that the win rates are actually lower when I switch from using simple playouts to using a neural network to value the board positions. The purple and pink lines use the same number of iterations, but use a neural network instead of playouts.
In contrast, just increasing the search iterations from 80 to 128 makes the player stronger.
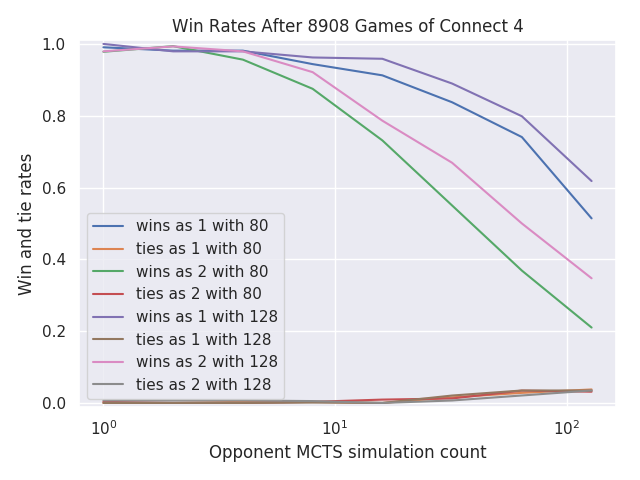
Here, all the players are using simple playouts. The player with 128 search iterations does better than 80 search iterations, and much better than the neural network.
I’ll try to run the same tests on the alpha-zero-general project to see if their neural network is actually helpful.
22 Feb 2019
I tried running the alpha-zero-general project’s Connect 4 player against my basic player without a neural network, and it was at least no worse than my basic player.
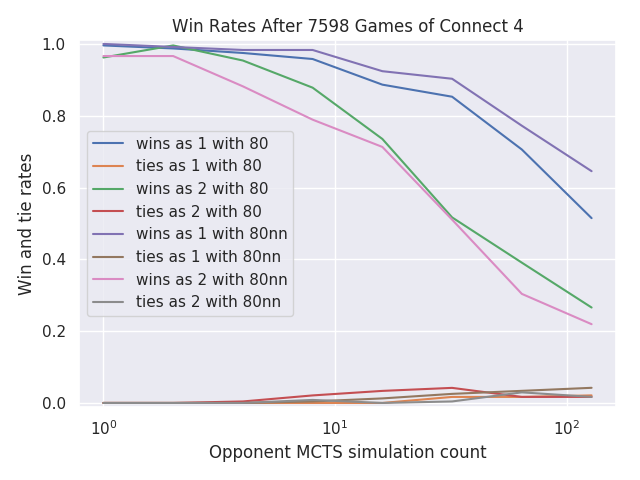
Something must be wrong with my neural network or my training, so I’m reading the original AlphaGo Zero paper. (The link at the bottom of the page gives free access.) One difference I noticed is that I haven’t implemented the idea of temperature in my loss function.
Also, their loss function uses mean squared error for the values, but cross entropy for the move policies. I use mean squared error for everything. I don’t know if I can mix things like that in the high-level API I’m using.
26 Feb 2019
I’ve been reading the AlphaGo Zero paper, and I found the AlphaZero paper (includes an open-access link). The AlphaZero supplementary material even includes some Python code as pseudocode for the algorithm! In that pseudocode, it looks like the player uses softmax sampling to choose a move for the first 30 moves of a game, then uses the best move from then on. I think this is related to the temperature algorithm I saw in the other paper.
28 Nov 2019
Since the machine learning was so frustrating, I started working on a PySide2 user interface. I just experimented with some ideas in the designer, but I didn’t really hook them up to anything.