When I created all my Chinese vocabulary flashcards, I just combined data from a bunch of places. The only significant work I did was converting the stroke order animations to static graphics. Following are descriptions of all the projects I used:
Character and word frequency
I found a web site that lists a bunch of Chinese language research results. The two pieces I was interested in were character frequency (sorted.zip) and phrase frequency (phrasesb5.zip). They’re just text files with the most common character or phrase at the top and several thousand entries in descending order. I included both of them in my subversion repository.
Chinese - English dictionary
This was part of the ZDT project. The database script is in the cedict subproject and originally came from the CEDICT project. I also used the dictionary in the adso subproject. I did not include either of these data files in my subversion repository, so you have to check out ZDT separately if you want to regenerate the flashcards yourself.
Stroke order
This also came from the ZDT project. The data file and a bunch of source code is in the strokeanimation subproject and seems to have originally come from Euroasia software. I used the static image style designed by the wiki commons stroke order project. I included the stroke order data file and some ZDT source code in my subversion repository. The data is very useful, but there’s a mix of fonts used. I really like this font:
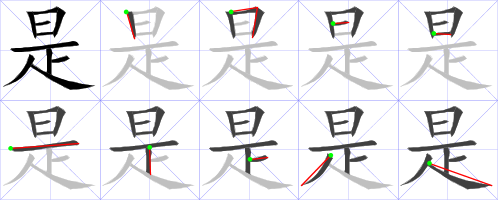
I’m less fond of this font:
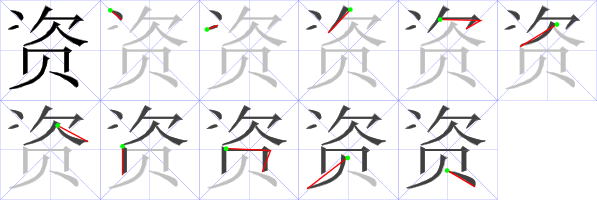
Some characters have errors, so create an issue if you find any problems. However, there seem to be inconsistencies between different stroke order authorities, so don’t panic if the stroke order disagrees with what you’ve been taught. If you really think that the stroke order is wrong on a character, please include a link to a source that I can verify.